
每次聊到我的資料科學工作,我幾乎都會提到 A/B 測試這個關鍵字。
很多人會問:「究竟為什麼需要 A/B 測試?」

不能只是「某人說了算」#
想像一下:會議室裡,公司某位官威很大的主管突然靈光一閃,提出一個他相信「絕對會讓用戶超愛」的功能。底下的人當然(只能)點頭如搗蒜,誰敢反對老闆的天才想法?
結果呢?六個月後,這個「超讚功能」不但沒有提升用戶體驗,反而讓產品表現變更爛,甚至收到用戶負評。
不管你做哪一行,你肯定也覺得這個情境不稀奇吧?
至少在我的工作經驗裡,這幾乎天天在上演。
這個現象即使在科技業也超常見,因為我們總是高估自己預測用戶喜好與行為的能力。身為資料科學家,我親眼看過太多經驗豐富的產品經理和設計師,他們當然都是聰明絕頂的人才,但依然有可能對用戶需求的判斷完全大錯特錯。甚至有研究與實際數據證明這點:
「在微軟進行 A/B 測試的想法中,只有三分之一能真的能改善商業指標」
《Trustworthy Online Controlled Experiments》.Ron Kohavi
人類的經歷累積出商業直覺,雖然很適合用來產生假設,但對於預測和評估產品改動的實際價值,表現很糟,連擁有世界級人才的科技巨頭都經常錯估。如果沒有 A/B 測試,我們基本上就是在瞎子摸象,濫用七嘴八舌的意見(而不是證據)來做決策。

(Source: unsplash)
A/B 測試:讓產品開發「很科學」#
A/B 測試把產品開發從「憑感覺」變成「科學」。透過隨機分配用戶到對照組和實驗組(稱為 隨機對照試驗),我們可以獨立衡量特定改動的因果效果,直接觀察「造成」用戶行為的實際效果(用商業指標來衡量)。我在 雷亞遊戲 擔任遊戲分析師時,就是用 A/B 測試來最佳遊戲教學流程,衡量出哪些新改動是真的對玩家黏著度有幫助的,用多項實驗提升了隔日留存率。
商業決策不只是要數據,而是要可信任、可行動的數據。
A/B 測試的厲害之處在於能過濾外在因素的雜訊,找出真正的因果關係。如果資料分析只看相關性,很容易被 混淆變項 誤導、看到虛假的相關(“Spurious Correlation”),而 A/B 測試提供的嚴謹統計方法、幫助我們做出可信的產品決策。A/B 測試的科學方法讓產品團隊能快速迭代,想法不行就快速失敗、快速改進。有可靠的產品迭代過程,產品的成長才有可能規模化。
A/B 測試是產品開發必備技能,連 AI 都需要實驗#
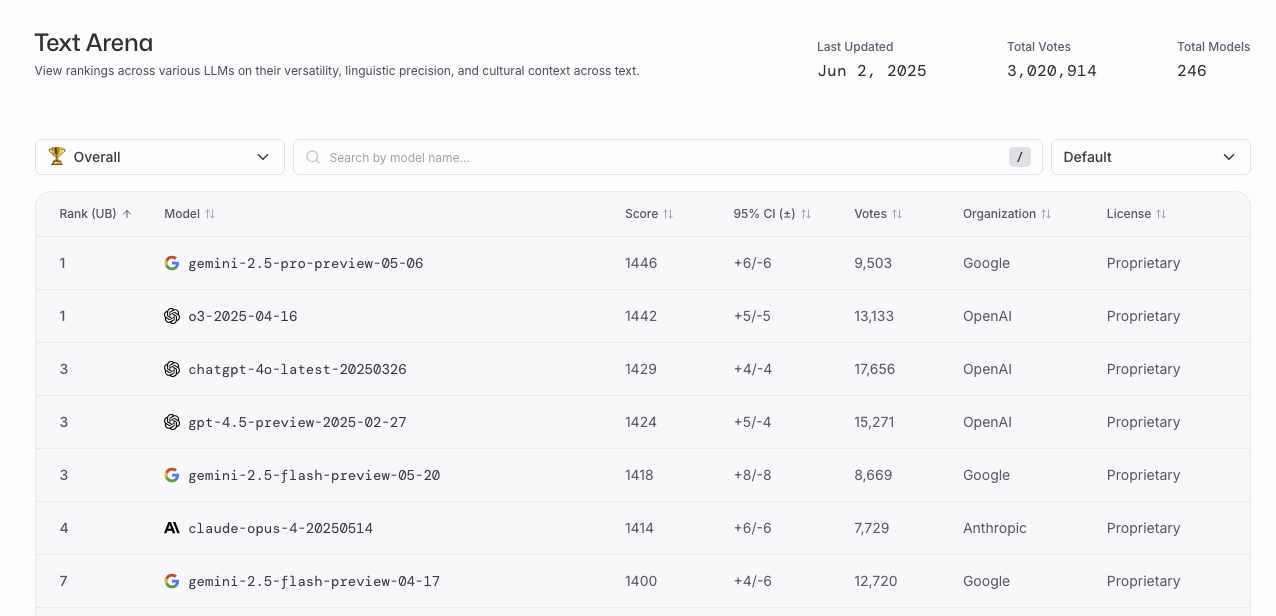
在技術跟產品都快速演進的時代,能夠快速且精準分辨什麼改動有效、什麼沒效,是決定產品存亡的關鍵因素。即使在 AI 時代,A/B 測試依然不可或缺。Chatbot Arena (lmarena.ai) 就是我很喜歡的範例,不同的 AI 模型要透過隨機對照試驗來「盲測」,以此衡量 AI 實際上到底好不好用,而不是只靠理論說嘴(例如 LLM 研究論文裡常用 BLEU、MRR 等離線指標)。連 AI 模型都需要 A/B 測試才能產生可信的表現分數排行榜(leaderboard):
不管你要設計新功能、AI 模型、還是 UI 介面,經過 A/B 測試的資料驗證永遠勝過瞎猜臆測
A/B 測試不只是「很加分」的分析方法,它是商業決策的必備工具。現在的實驗服務很成熟(例如第三方實驗平台 Eppo),任何公司都能做到同時跑數百個實驗,從按鈕顏色到演算法改動的各種變化都可以測試,在幾十年前根本不可能取得的數據洞察、現在可以輕鬆取得。
更重要的是,A/B 測試也是開發過程的風險控管工具,讓產品能在一小群用戶先測試改動,確認沒問題才全面推出(這稱為 Canary Test),要是團隊不小心搞砸了,才不會一次讓所有你的忠實客戶同時崩潰、釀成大災難。幾乎你想得到的科技公司,從 Google、Netflix、到 Booking.com 等等,商業實驗早已植入公司 DNA,把每個產品改動都當成「需要測試」的假設,而不是鴕鳥心態,每個想法都不問好壞直接實踐並上線。
我個人主觀相信:有 A/B 測試與因果推論的商業決策,才是真正的 Data-Driven。否則,都只是瞎猜。
推薦閱讀:
- A/B 測試領域必讀聖經:《Trustworthy Online Controlled Experiments》.Ron Kohavi
- A/B 測試的入門科普書:《數據分析的力量》
- 台灣少數的 A/B 測試與因果推論中文翻譯書
- 是被書名耽誤的好書 ˊ_>ˋ